PSR-StarGAN-VC
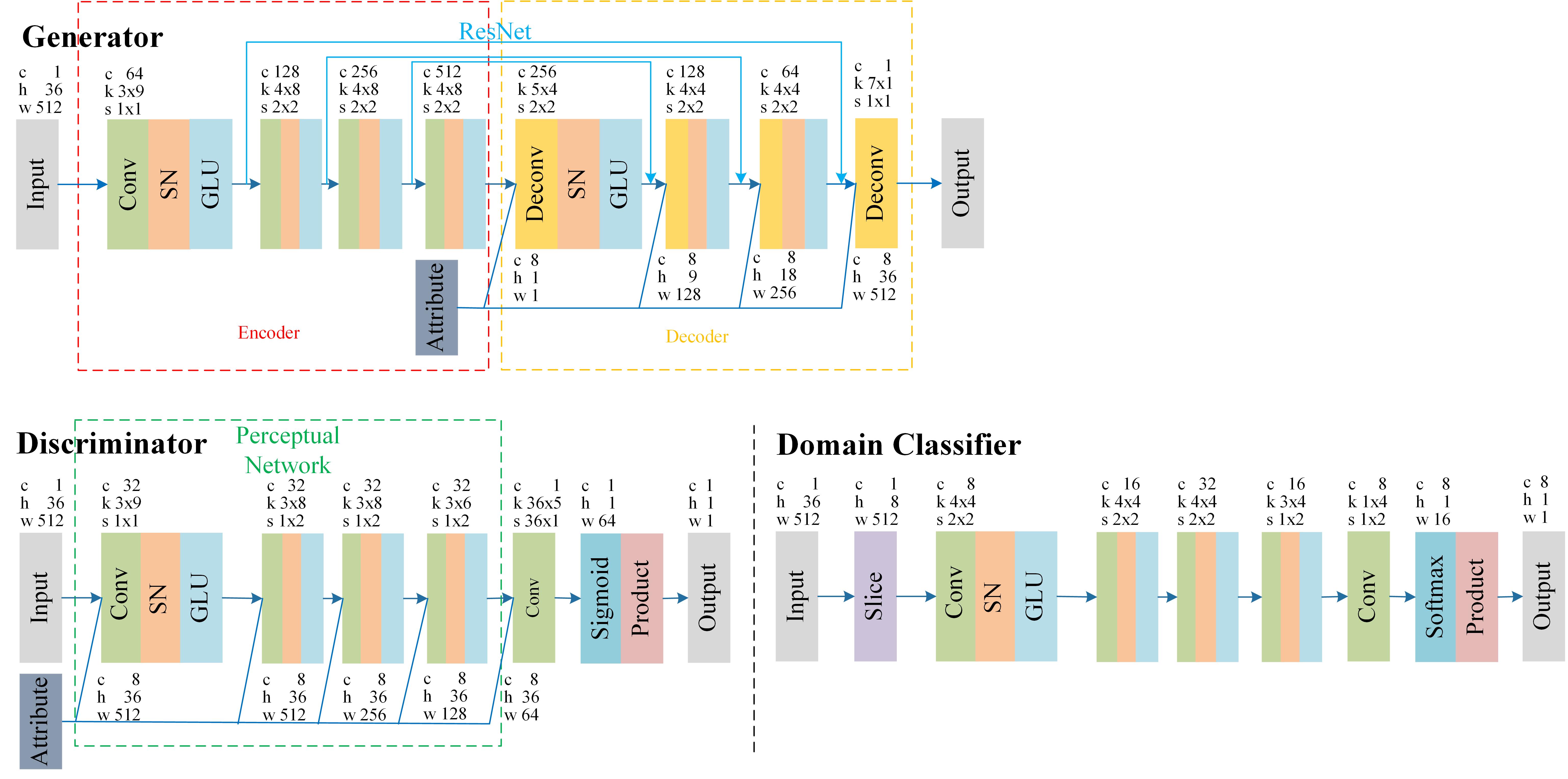
StarGAN-VC was recently proposed, which utilizes a variant of Generative Adversarial Networks (GAN) to perform non-parallel many-to-many VC. However, the quality of generated speech is not satisfactory enough. An improved method named “PSR-StarGAN-VC” is proposed in this paper by incorporating three improvements. Firstly, perceptual loss functions are introduced to optimize the generator in StarGAN-VC aiming to learn high-level spectral features. Secondly, considering that Switchable Normalization (SN) could learn different operations in different normalization layers of model, it is introduced to replace Batch Normalization (BN) in StarGAN-VC. Lastly, Residual Network (ResNet) is applied to establish the mapping of different layers between the encoder and decoder of generator aiming to retain more semantic features when converting speech, and to reduce the difficulty of training. Experiment results on the VCC 2018 datasets demonstrate superiority of the proposed method in terms of naturalness and speaker similarity.
The demo of PSR-StarGAN-VC
Task and dataset- We evaluated our method on non-parallel multi-speaker VC task.
- We used the Voice Conversion Challenge 2018 (VCC 2018) dataset in which we selected a subset of speakers as covering all inter- and intra-gender conversions: VCC2SF3, VCC2SF4, VCC2SM3, VCC2SM4, VCC2TF1, VCC2TF2, VCC2TM1, and VCC2TF2. Converted speech by PSR-StarGAN-VC is avaliable in converted speech of PSR-StarGAN-VC.
- In order to compare converted speech by PSR-StarGAN-VC with official demo of StarGAN-VC, we need to select the same speakers as they select. Experiments are carried out on four speakers (SF1, SF2, SM1, and SM2).
Comparison between StarGAN-VC and PSR-StarGAN-VC
Notation
- Source is the source speech samples.
- Target is the target speech samples. They are provided as references. Note that we did not use these data during training.
- StarGAN-VC is the converted speech samples, in which the baseline StarGAN-VC was used to convert mel-cepstral coefficients (MCCs).
- PSR-StarGAN-VC is the converted speech samples, in which the proposed PSR-StarGAN-VC was used to convert mel-cepstral coefficients (MCCs).
Male (VCC2SM1) → Female (VCC2SF1)
| Source | Target | StarGAN-VC (Baseline) |
PSR-StarGAN-VC (Proposed) |
|
|---|---|---|---|---|
| Sample 1 | ||||
| Sample 2 | ||||
| Sample 3 |
Female (VCC2SF2) → Male (VCC2SM2)
| Source | Target | StarGAN-VC (Baseline) |
PSR-StarGAN-VC (Proposed) |
|
|---|---|---|---|---|
| Sample 1 | ||||
| Sample 2 | ||||
| Sample 3 |
Male (VCC2SM2) → Male (VCC2SM1)
| Source | Target | StarGAN-VC (Baseline) |
PSR-StarGAN-VC (Proposed) |
|
|---|---|---|---|---|
| Sample 1 | ||||
| Sample 2 | ||||
| Sample 3 |
Female (VCC2SF1) → Female (VCC2SF2)
| Source | Target | StarGAN-VC (Baseline) |
PSR-StarGAN-VC (Proposed) |
|
|---|---|---|---|---|
| Sample 1 | ||||
| Sample 2 | ||||
| Sample 3 |
NOTE:
- Recommended browsers are Apple Safari, Google Chrome, Mozilla Firefox, or Microsoft Edge.
- If wave files in this webpage could not be played as expected, you may download here directly.
- If you want to cite this paper, try this: Yanping Li, Dongxiang Xu, Yan Zhang, Yang Wang, Binbin Chen, "Non-parallel Many-to-many Voice Conversion with PSR-StarGAN," (Accepted by Interspeech 2020)